NATS101
Internet Engineering
Spring 2024@1995parham
History
- NATS is a high-performance messaging system created by Derek Collison in 2010 written in Ruby.
- It was originally built to serve as the message bus for Cloud Foundry
- Handling internal communication among components of the system
It Addresses
- Service Discovery
- Low latency communication
- Load balancing
- Notification and events handling
Overview
- Client publishes message on
foo
subject - Only clients subscribed to
foo
receive the message
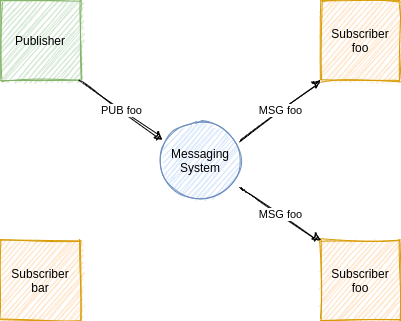
How Simple!
INFO {"server_id":"NCNS32OEKOMMHTBVUYC7QWASFAP3BPEKGZG3QDIYRCBUL23WE3OVVBBO","server_name":"NCNS32OEKOMMHTBVUYC7QWASFAP3BPEKGZG3QDIYRCBUL23WE3OVVBBO","version":"2.1.7","proto":1,"git_commit":"bf0930e","go":"go1.13.10","host":"0.0.0.0","port":4222,"max_payload":1048576,"client_id":1,"client_ip":"172.17.0.1"}
SUB greetings 1
+OK
PUB greetings 12
Hello World!
+OK
MSG greetings 1 12
Hello World!
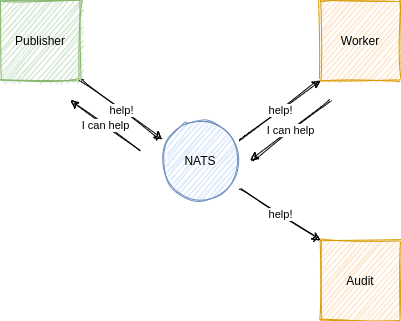
Request/Response
- Client connected to NATS publishes a request on a
help
subject - Worker client subscribed to
help
, processes requests, then sends response - Audit client is subscribed to all subjects via a wildcard, so also receives message but does not reply
- Publisher receieves the response from the worker client
Request/Response (cont'd)
- A publisher sends a message on a particular subject by attaching a reply subject name along with it.
- Then, the subscribers who receive this message send the response to the reply subject that was specified in the request message.
- Reply subjects have a unique name called inbox and the NATS server will send the message comming into these subjects to the relevant publisher.
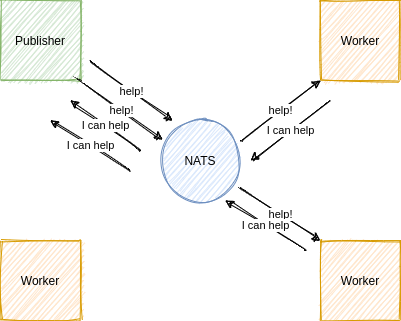
Queue
- Publisher sends multiple help requests on a
help
subject - Multiple worker clients subscribed to the
help
subject from a distributed queue - Each published request is randomly balanced to only one of the worker clients in the distributed queue
NATS As an Always Available Dial Tone
- The main design constraints that define the style of the NATS project are:
- Simplicity
- Performance
- Reliability
- It does not offer any Persistence or Buffering
- It is true Fire and Forget
Availability
- NATS will try to protect itself at all costs to be available for all users
- NATS client libraries, internally try to have an always established connection to one of the available NATS servers
- In case a server fails, NATS will reconnect to another available server in the pool
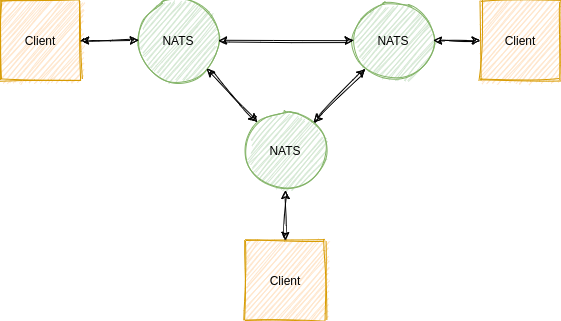
- NATS supports high-availablity via a clustering mode that is set up as a full-mesh of the servers
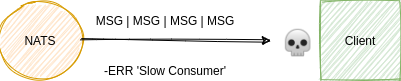
Slow Consumer
- By default, if a client fails to drain the pending data that the server is holding for the client for over two seconds, the server will disconnect the client
- Read more about it here
Ping/Pong
- There is a PING/PONG interval happing that the client has to follow otherwise the server will reset the connection in case there are many PONG replies missing.
- Server sends PING messages to client in each interval and client has to respond
- Client also can send PING messages to the server

Subject Names
- The dot character (.) has special meaning as part of the subject.
- When using it as part of the subject, we can create namespaces (hierarchy) that can be later matched via wildcards.
| Subject | Matches |
|---|---|
| foo.*.bar | foo.hello.bar ✅, foo.hi.bar ✅ |
| foo.* | foo.hello ✅, foo.hi.bar ❌ |
| foo.> | foo.hello.bar ✅, foo.hi.bar ✅, foo.hello ✅ |
*: matches a single token>: matches one or more tokens in the subject, and it can only appear at the end
Queue Subscribtions: Hands-on
Worker 1 👷
INFO {"server_id":"NARXYLU3XEZSFYCFRV5WJ63GQS5WDV3WC4WAKCYDYY2IBGIETWJADZVS","server_name":"NARXYLU3XEZSFYCFRV5WJ63GQS5WDV3WC4WAKCYDYY2IBGIETWJADZVS","version":"2.1.8","proto":1,"git_commit":"c0b574f","go":"go1.14.8","host":"0.0.0.0","port":4222,"max_payload":1048576,"client_id":4,"client_ip":"172.22.0.1"}
SUB requests workers 5
+OK
MSG requests 5 6
second
Worker 2 👷
INFO {"server_id":"NARXYLU3XEZSFYCFRV5WJ63GQS5WDV3WC4WAKCYDYY2IBGIETWJADZVS","server_name":"NARXYLU3XEZSFYCFRV5WJ63GQS5WDV3WC4WAKCYDYY2IBGIETWJADZVS","version":"2.1.8","proto":1,"git_commit":"c0b574f","go":"go1.14.8","host":"0.0.0.0","port":4222,"max_payload":1048576,"client_id":5,"client_ip":"172.22.0.1"}
SUB requests workers 55
+OK
MSG requests 55 5
first
Publisher ✍️
INFO {"server_id":"NARXYLU3XEZSFYCFRV5WJ63GQS5WDV3WC4WAKCYDYY2IBGIETWJADZVS","server_name":"NARXYLU3XEZSFYCFRV5WJ63GQS5WDV3WC4WAKCYDYY2IBGIETWJADZVS","version":"2.1.8","proto":1,"git_commit":"c0b574f","go":"go1.14.8","host":"0.0.0.0","port":4222,"max_payload":1048576,"client_id":6,"client_ip":"172.22.0.1"}
PUB requests 5
first
+OK
PUB requests 6
second
+OK
Even More Features!
- Jetstream 🚀
- Clustering ✨
- Super-Cluster with Gateways 🗺️
Jetstream
- JetStream is a NATS built-in distributed persistence system.
- JetStream is built-in to nats-server and you only need 1 (or 3 or 5 if you want fault-tolerance against 1 or 2 simultaneous NATS server failures) of your NATS server(s) to be JetStream enabled for it to be available to all the client applications.
Functionalities enabled by JetStream
- Streaming: temporal decoupling between the publishers and subscribers
- Replay policies
- Retention policies and limits
- Persistent distributed storage
- Stream replication factor
- Mirroring between streams
- De-coupled flow control
- Exactly once semantics
Streaming
temporal decoupling between the publishers and subscribers
Subscribers only receive the messages that are published when they are actively connected to the messaging system (i.e. they do not receive messages that are published while they are not subscribing or not running or disconnected).
However, nowadays a new way to provide this temporal de-coupling has been devised and has become 'mainstream': streaming.
Streams capture and store messages published on one (or more) subject and allow client applications to create subscribers (i.e. JetStream consumers) at any time to replay (or consume) all or some of the messages stored in the stream
Replay policies
JetStream consumers support multiple replay policies.
- all of the messages currently stored in the stream, meaning a complete replay and you can select the replay policy(i.e. the speed of the replay) to be either:
- instant
- the messages are delivered to the consumer as fast as it can take them.
- original
- the messages are delivered to the consumer at the rate they were published into the stream, which can be very useful for example for staging production traffic.
- the last message stored in the stream, or the last message for each subject (as streams can capture more than on subject).
- starting from a specific sequence number.
- starting from a specific start time.
Retention policies and limits
Practically speaking, streams cannot always just keep growing forever and therefore JetStream support multiple retention policies as well as the ability to impose size limits on streams.limit
You can impose the following limits on a stream
- Maximum message age
- Maximum total stream size (in bytes)
- Maximum number of messages in the stream
- Maximum individual message size
- You can also set limits on the number of consumers that can be defined for the stream at any given point in time.
You must also select a discard policy which specifies what should happen once the stream has reached one of its limits and a new message is published
- discard old means that the stream will automatically delete the oldest message in the stream to make room for the new messages.
- discard new means that new message is discarded (and the JetStream publish call retuns an error indicating that a limit was reached)
Retention policy
You can choose what kind of retention you want for each stream
- limits (the default)
- interest (messages are kept in the stream for as long as there are consumers that haven't delivered the message yet).
- work queue (the stream is used as a shared queue and messages are removed from it as they consumed)
Regardless of the retention policy selected, the limits (and the discard policy) always apply.
Persistent distributed storage
You can choose the durability as well as the resilience of the message store according to your needs.
- Memory storage
- File storage
- Replication (1 (none), 2, 3) between nats servers for Fault Tolerance
JetStream uses a NATS optimized RAFT distributed quorom algorithm to distribute the persistence service between nats servers in a cluster while maintaining immediate consistency even in the face of Byzantine failures.
In JetStream the configuration for storing messages is defined separately from how they are consumed.
Storage is defined in a Stream and consuming messages is defined by multiple Consumers.
Stream replication factor
A stream's replication factor (R, often referred to as the number Replicas) determines how many places it is stored allowing you to tune to balance risk with resource usage and performance.
A stream that is easily rebuilt or temporary might be memory based with a R=1 and a stream that can tolerate some downtime might be file based with R=1.
| Replicas | Description |
|---|---|
| 1 | Cannot operate during an outage of the server servicing the stream. Highly performant. |
| 2 | No significant benefit at this time. We recommend using Replicas=3 instead. |
| 3 | Can tolerate loss of one server servicing the stream. An ideal balance between risk and performance. |
| 4 | No significant benefit over Replicas=3 except marginally in a 5 node cluster. |
| 5 | Can tolerate simultaneous loss of two servers servicing the stream. Mitigates risk at the expense of performance. |
Mirroring between streams
JetStream also allows server administrators to easily mirror streams, for example between different JetStream domains in order to offer disaster recovery.
You can also define a stream as one of the sources for another stream.
De-coupled flow control
JetStream provides de-coupled flow control over streams, the flow control is not 'end to end' where the publisher(s) are limited to publish no faster than the slowest of all the consumers (i.e. the lowest common denominator) can receive, but is instead happening individually between each client application (publishers or consumers) and the nats server.
Exactly once semantics
Because publications to streams using the JetStream publish calls are acknowledged by the server, the base quality of service offered by streams is at least once.
Meaning that while reliable and normally duplicate free there are some specific failure scenarios:
- That could result in a publishing application believing (wrongly) that a message was not published successfully and therefore publishing it again.
- That could result in a client application's consumption acknowledgement getting lost and therefore the message being re-sent to the consumer by the server.
Therefore, JetStream also offers an exactly once.
- For the publishing side it relies on the publishing application attaching a unique message or publication id in a message header and on the server keeping track of those ids for a configurable rolling period of time in order to detect the publisher publishing the smae message twice.
- For the subscribers a double acknowledgement mechanisim is used to avoid a message being erroneously re-sent to a subscriber by the server after some kinds of failures
Consumers
JetStream consumers are views on a stream, they are subscribed to (or pulled) by client applications to receive copies of (or to consume if the stream is set as a working queue) message stored in the strem.Fast push consumers
Client applications can choose to use fast un-acknowledged push (ordered) consumers to receive messages as fast as possible (for the selected replay policy) on a specific delivery subject or to an inbox.
Horizentally scalable pull consumers with batching
Client applications can also use and share pull consumers that are demand-driven, support batching and must explicitly acknowledge message reception and processing which means that they can be used to consume (ie.e use the stream as a distributed queue) as well as process the messages in a stream.
Pull consumers can and are meant to be shared between applications (just like queue groups) in order to provide easy and transparent horizental scalability of the processing or consumption of messages in a stream without having (for example) to worry about having to define partitions or worry about fault-tolerance.
References 📚
- Practical NATS: From Beginner to Pro, Book by Waldemar Quevedo
- NATS Documentation
